AI Infra 面经
1. CUDA 基础
1.1 CUDA 存储体系结构及存储的优缺点
CUDA的存储体系结构包括全局内存(Global Memory)、共享内存(Shared Memory)、常量内存(Constant Memory)/ 纹理内存(Texture Memory)和本地内存(Local Memory)。
全局内存(Global Memory) GPU中最大的内存(即 HBM 内存),可以被所有块上的所有线程访问。然而,访问全局内存通常比其他内存类型慢,因此需要进行优化以避免性能下降,常见优化手段:合并内存访问和使用共享内存。
共享内存(Shared Memory) 同一个 Block 内的线程可以通过共享内存共享数据。相比访问全局内存至少快10倍。但共享内存的容量有限(A100 192 KB/SM),无法被其他线程块访问。
纹理内存和常量内存(Texture and Constant Memory) GPU 中的特殊内存类型,针对访问特定数据类型(例如纹理或常量值)进行了优化。所有块中的所有线程都可以访问这些内存类型。 例如,常量内存专门只能用于存储只读数据,纹理内存只能用于存储二维图像数据,这两种内存类型的访问速度都相当快,可以与共享内存相媲美。 因此,使用纹理内存和常量内存的目的是优化数据访问并减少共享内存的计算负载。我们可以将一部分数据分配给纹理内存和常量内存,而不是将所有数据推送到共享内存中。这种分配策略通过利用纹理内存和常量内存的优化访问功能来帮助增强内存性能。
本地内存(Local Memory) 每个线程都可以使用自己的本地内存,可以在其中存储临时变量。专用于每个单独的线程。
1.2 CUDA stream
stream 相当于是GPU上的任务队列(即命令流水线),许多个CUDA操作在不同的stream中并行执行,从而提高GPU的利用率和性能。 每个kernel调用或大多数CUDA API都可以指定关联到某一个stream,同一个stream的任务是严格保证顺序的,上一个命令执行完成才会执行下一个命令。
不同stream的命令不保证任何执行顺序,部分优化技巧需要用到多个 stream 才能实现。如在执行kernel的同时进行数据拷贝,需要一个 stream 执行 kernel,另一个 stream 进行数据拷贝,或者针对大数据集进行切分,然后可以采用多个stream 执行并行加速拷贝。
此外,多个 stream 还能够方便地划分和管理不同的任务,提高应用程序的灵活性和可扩展性。
1.3 global mem → shared mem 过程
线程从 global memory 经过 L1/L2 cache 加载到寄存器,再显式写入 shared memory。
具体地说,线程发起 load 指令 smem[i] = gmem[j] 时,编译器对应生成 ld.global + st.shared 的 PTX 指令组合,然后,会访问 L1 Cache,没有命中则发往 L2 Cache,L2 也没有命中的话,会去 HBM 上,数据按照 cache line 为单位搬运,数据放入寄存器后通过 st.shared 写入 shared mem。
但是,在 Ampere 架构后,引入 cp.async 指令,能直接从全局内存加载数据到SM共享内存中(只过 L2 Cache),省略了中间寄存器文件(RF)的过程。
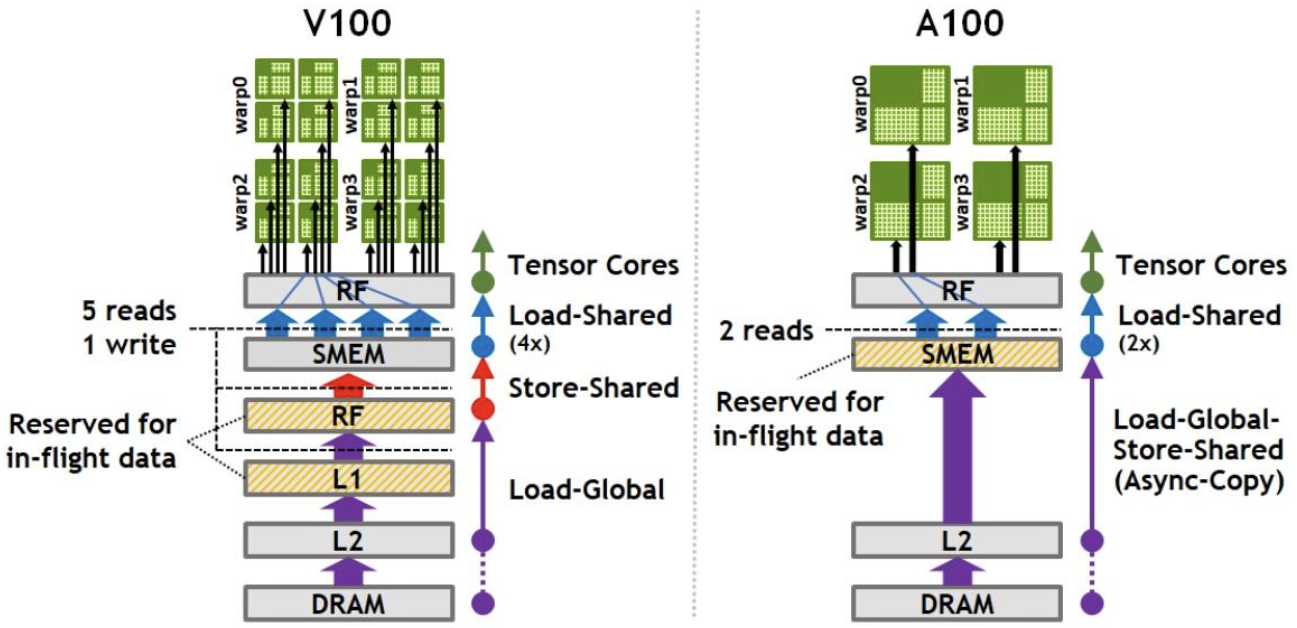
L1 Cache 是每个 SM 内独有的(和 smem 在物理上是一块存储),L2 Cache 是全局共享的。
1.4 全局内存访问模式
Global Mem 有合并访存和非合并访存两种模式,若一个 warp 对 global Mem 的依次访问导致最少的数据传输,则是合并访存,否则是非合并访存。这里,最少数据传输是指:一个 warp 的内存访问恰好覆盖所需的最少数量的 sector(每个 sector = 32B,每个 sector 中都是所需的数据),并且这些 sector 的地址连续对齐。
1.4 性能分析工具
Block_size 对 SM 可启动 warp 数量的影响,下面以 8.9 举例,GPU (8.9)
Roof model 与 访存瓶颈、计算瓶颈
1.5 Bank 冲突与解决方案
每个 Bank 是 4 字节