CUDA-Operators-1-SGEMV
本系列文章重点阐述了各类算子的逐步优化过程,涵盖 CUDA 常用算子,并对不同算子的性能瓶颈进行分析。各类算子完整代码请参考个人仓库 OpenKernels。
1.SGEMV
SGEMV 表达式为:$Y = A * X$,其中 A(M, K),X(K, 1),Y(M,1)。本文展示了 K=32,K=128,K=16 和 Large K 四种情况下,优化 GEMV 算子的思路和方法。
最 Naive 的 GEMV 计算流程如图 Fig 1 所示,一个线程算 Y 中一个数,即每个线程从 global mem 读取 A 的一行向量,再读取 X 向量,两个向量进行内积。数据利用率低,访存效率低。
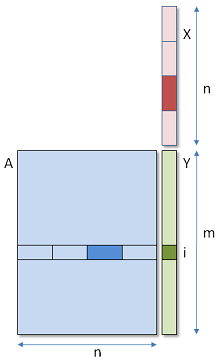
总体优化思路如下:
- 尽可能让 warp 的 32 个线程繁忙:主要针对 n < 32 的情况,例如
K=16的特例,可以让一个 warp 处理多行元素。 - 尽可能地提高访存效率
- global mem->register:从 Global Mem 搬数到寄存器上时,最重要的是否考虑了合并访存。
- shared mem->register:每个 warp 都需要对向量 X 进行一次 global 上的访存,所以一个 block 访存四次。如果将 X 存储到 shared mem 中,四个 warp 访问 shared mem 上的 X。那么,对于 global 的访存次数从 4 次变成 1 次。但是,从 global mem → shared mem 搬数需要同步,会带来额外的开销,可能导致性能下降。
1.1 K=32
对于 K % 32 == 0 的情况,我们将每个 block 设置为 128,4 个 warp,每个 warp 负责一行元素计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#define WARP_SIZE 32
#define OFFSET(row, col, ld) ((row) * (ld) + (col))
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0])
template <unsigned int WarpSize>
__device__ __inline__ float warp_reduce_sum_f32(float sum){
if (WarpSize >= 32) sum += __shfl_xor_sync(0xffffffff, sum, 16);
if (WarpSize >= 16) sum += __shfl_xor_sync(0xffffffff, sum, 8);
if (WarpSize >= 8) sum += __shfl_xor_sync(0xffffffff, sum, 4);
if (WarpSize >= 4) sum += __shfl_xor_sync(0xffffffff, sum, 2);
if (WarpSize >= 2) sum += __shfl_xor_sync(0xffffffff, sum, 1);
return sum;
}
/**
* block(32, 4)
* grid((M+4-1) / 4)
*/
__global__ void sgemv_k32_f32_kernel(float* a, float* b, float* c, const int M, const int K){
int tx = threadIdx.x; // 0~31
int ty = threadIdx.y; // 0~4
int bx = blockIdx.x; // 0~M/4
int lane = tx % WARP_SIZE;
int m = bx * blockDim.y + ty;
if (m < M){
float sum = 0;
int niter = (K + WARP_SIZE -1) / WARP_SIZE;
for (int i = 0; i < niter; ++i){
int tid_in_block = i * WARP_SIZE + lane;
sum += a[OFFSET(m, tid_in_block, K)] * b[tid_in_block];
}
sum = warp_reduce_sum_f32<WARP_SIZE>(sum);
if (lane == 0) c[m] = sum;
}
}
1.2 K=128
对于 K % 128 == 0 的情况,同样让 warp 负责一行元素的计算,但是因为每行的元素比较多,所以采用了float4进行向量化的访存。能够有更高的访存效率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// dim3 block = dim3(32, 4)
// grid grid = dim3((K + block.y - 1) / block.y)
__global__ void sgemv_k128_f32x4_kernel(float *a, float *b, float *c, int M, int K) {
int tx = threadIdx.x;
int ty = threadIdx.y;
int bx = blockIdx.x;
int lane = tx % WARP_SIZE;
int m = bx * blockDim.y + ty;
if (m < M){
float sum = 0;
int niter = (K + WARP_SIZE * 4 - 1) / (WARP_SIZE * 4);
for (int w = 0; w < niter; w++){
int tid_in_block = 4 * (w * WARP_SIZE + lane);
float4 cur_a = FLOAT4(a[OFFSET(m, tid_in_block, K)]);
float4 cur_b = FLOAT4(b[tid_in_block]);
sum += cur_a.x * cur_b.x;
sum += cur_a.y * cur_b.y;
sum += cur_a.z * cur_b.z;
sum += cur_a.w * cur_b.w;
}
sum = warp_reduce_sum_f32<WARP_SIZE>(sum);
if(lane == 0) c[m] = sum;
}
}
1.3 K=16
当 K 维度特别小的时候,让一个 warp 负责两行元素的计算。比如,warp0 中,0-15 号线程负责第0行元素的计算,而 16-31 号线程负责第 1 行元素的计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/**
* block(32, 4)
* grid( (K + 4*2 -1) / (4*2) )
*/
template <const int ROW_PER_WARP = 2>
__global__ void sgemv_k16_f32_kernel(float *a, float *b, float *c, int M, int K) {
constexpr int WARP_K = (WARP_SIZE + ROW_PER_WARP -1) / ROW_PER_WARP;
int tx = threadIdx.x;
int ty = threadIdx.y;
int bx = blockIdx.x;
int lane = tx % WARP_SIZE;
int inner_col = lane % WARP_K;
int inner_row = lane / WARP_K;
int k = lane % WARP_K;
int m = bx * blockDim.y * ROW_PER_WARP + ty * ROW_PER_WARP + inner_row;
if (m < M){
float sum = 0;
sum = a[OFFSET(m, k, K)] * b[k];
sum = warp_reduce_sum_f32<WARP_K>(sum);
if (k == 0) c[m] = sum;
}
}
1.4 Large K
当 K 维度变得特别大,而 M 比较小时,例如 M=256, K=65535 时,再让一个 warp 算一行,每个线程需要沿 K 维度迭代计算 K / 32 次,严重影响并行效率。所以采用和 Split-K 策略进行优化,让多个 Block 负责一行数据的计算,Block 之间使用 atomicAdd 进行归约。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
/**
* Every Blcok calculate (BM, SPLIT_K)
* const int BM = 4;
* const int BK = WARP_SZIE;
* const int SPLIT_K = 2048;
* dim3 block(WARP_SZIE ,BM);
* dim3 grid((K + SPLIT_K -1) / SPLIT_K, (M + BM -1) / BM);
*/
template <const int BM, const int BK, const int SPLIT_K>
__global__ void sgemv_splitk_f32_kernel(float *a, float *b, float *c, int M, int K){
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int m = by * BM + ty;
int lane = tx % WARP_SIZE;
if (m < M){
float sum = 0;
int niter = SPLIT_K / WARP_SIZE / 4;
for (int w = 0; w < niter; ++w){
int k = bx * SPLIT_K + (w * WARP_SIZE + lane) * 4;
float4 reg_x = FLOAT4(a[OFFSET(m, k, K)]);
float4 reg_y = FLOAT4(b[k]);
sum += reg_x.x * reg_y.x;
sum += reg_x.y * reg_y.y;
sum += reg_x.z * reg_y.z;
sum += reg_x.w * reg_y.w;
}
sum = warp_reduce_sum_f32<WARP_SIZE>(sum);
if (lane == 0) atomicAdd(&c[m], sum);
}
}
1.5 Split-K w/ smem
我们使用 shared mem 缓存了 X 向量,但是由于需要引入同步,会产生额外的开销,在 RTX 4060 上效果往往不如直接 Split-K,具体代码和实验结果如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
/**
* Every Blcok calculate (BM, SPLIT_K)
* const int BM = 4;
* const int BK = WARP_SZIE;
* const int SPLIT_K = 2048;
* dim3 block(WARP_SZIE ,BM);
* dim3 grid((K + SPLIT_K -1) / SPLIT_K, (M + BM -1) / BM);
* size_t shared_mem_bytes = SPLIT_K * sizeof(float);
*/
template <const int BM, const int BK, const int SPLIT_K>
__global__ void sgemv_splitk_smem_f32_kernel(const float * __restrict__ A,
const float * __restrict__ B,
float * __restrict__ C,
int M, int K) {
extern __shared__ float smem_b[];
const int bx = blockIdx.x;
const int by = blockIdx.y;
const int tx = threadIdx.x; // 0..BK-1
const int ty = threadIdx.y; // 0..BM-1
const int block_threads = BK * BM;
const int tid = ty * BK + tx;
const int lane = tx;
const int m = by * BM + ty;
// compute tile range in K dimension
const int k_start = bx * SPLIT_K;
const int k_end = min(k_start + SPLIT_K, K);
const int tile_len = k_end - k_start;
for (int idx = tid; idx < tile_len; idx += block_threads) {
smem_b[idx] = B[k_start + idx];
}
__syncthreads();
if (m < M){
float sum = 0.0f;
for (int k_local = lane; k_local < tile_len; k_local += BK) {
float a_val = A[m * K + (k_start + k_local)];
float b_val = smem_b[k_local];
sum += a_val * b_val;
}
sum = warp_reduce_sum_f32<WARP_SIZE>(sum);
if (lane == 0) {
atomicAdd(&C[m], sum);
}
}
}
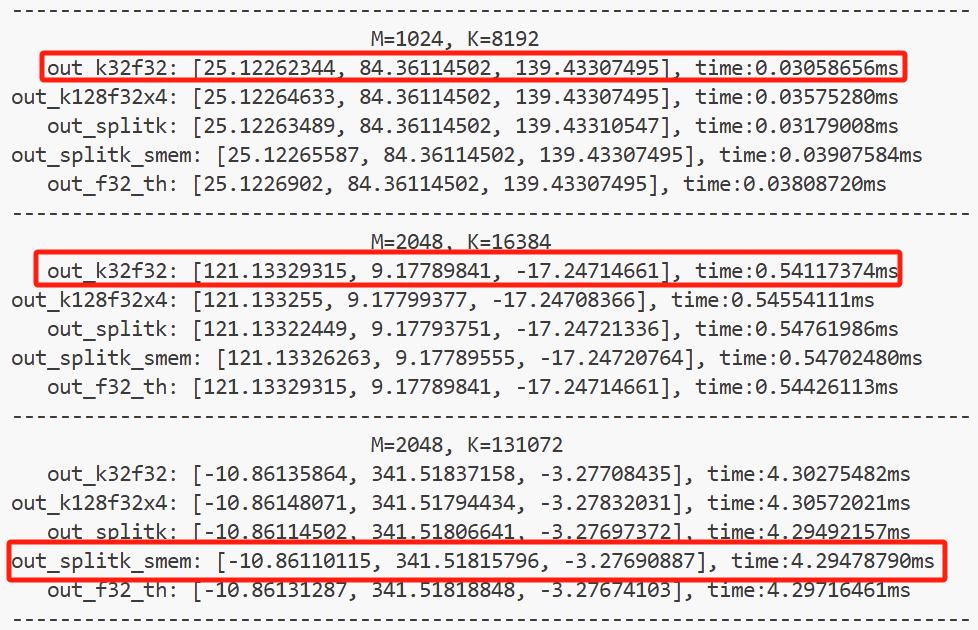
warp up 10 轮,测试 200 轮的结果如下图所示。 红框代表最佳的方案。
reference
[1] DefTruth, Many Others. LeetCUDA: A Modern CUDA Learn Notes with PyTorch for Beginners. 2025. https://github.com/xlite-dev/LeetCUDA.git.
[2] 深入浅出GPU优化系列:gemv优化. https://zhuanlan.zhihu.com/p/494144694