CUDA-Operators-3-SGEMM
本系列文章重点阐述了各类算子的逐步优化过程,涵盖 CUDA 常用算子,并对不同算子的性能瓶颈进行分析。各类算子完整代码请参考个人仓库 OpenKernels。
SGEMM
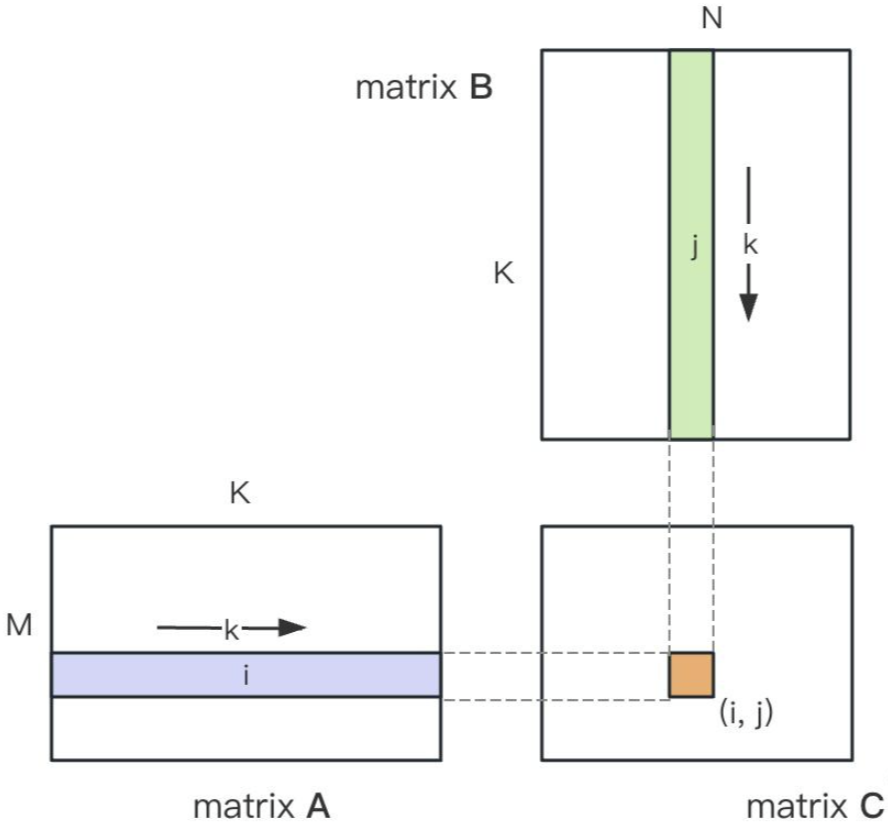
通用矩阵乘(GEMM)计算公式为:$C=\alpha AB + \beta C$,核心部分是矩阵 A 和 $B$ 相乘。下面进行计算复杂度分析,矩阵 A 维度通常为 (M, K),矩阵 B 维度通常为 (K, N),则 C 的维度为 (M, N)。如图 1 所示,C 中每个元素是矩阵 A 一行和矩阵 B 一列内积的结果,即计算一个元素需要 K 次乘法和 K-1 次加法,共计 2K-1 次浮点运算。另外,AB 和 C 的放缩通常需要 MN 次浮点运算,AB 和 C 放缩后再相加需要 MN 次,因此总浮点运算数为 (2K+2)MN 次。由于 K»2,通常视作 2KMN 次浮点运算。
而 SGEMM 则是指单精度通用矩阵乘,为简便计算,下面的 $\alpha$ 和 $\beta$ 分别设置为 1 和 0。
Naive SGEMM Kernel
使用 CUDA 实现最基础的 SGEMM,Kernel 代码如下所示。每个线程计算矩阵 C 中一个数,共使用 M * N 个线程完成整个矩阵的计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// #define OFFSET(row, col, ld) ((row) * ld + col)
// dim3 block(32, 32);
// dim3 grid((N + block.x - 1) / block.x, (M + block.y - 1) / block.y);
__global__ void naiveSgemmkernel(float* __restrict__ a, float* __restrict__ b, float* __restrict__ c,
const int M, const int N, const int K, const float alpha, const float beta
){
int m = blockIdx.y * blockDim.y + threadIdx.y;
int n = blockIdx.x * blockDim.x + threadIdx.x;
if (m < M && n < N){
float sum = 0.0f;
for (int k = 0; k < K; ++k){
sum += a[OFFSET(m, k, K)] * b[OFFSET(k, n, N)];
}
c[OFFSET(m, n, N)] = alpha * sum + beta * c[OFFSET(m, n, N)];
}
}
矩阵 A,B,C 均是在 global memory 上。下面来分析一下该 kernel 函数中 A、B、C 三个矩阵对 global memory 的读取和写入情况。
读取 Global Memory:
对于矩阵 C 中每一个元素计算, 需要读取矩阵 A 中的一行元素;
对于矩阵 C 中同一行的 n 个元素, 需要重复读取矩阵 A 中同一行元素 n 次;对于矩阵 C 中每一个元素计算, 需要读取矩阵 B 中的一列元素;
对于矩阵 C 中同一列的 m 个元素, 需要重复读取矩阵 B 中同一列元素 m 次;
写入 Global Memory:矩阵 C 中的所有元素只需写入一次。
由此可见:
- 对 A 矩阵重复读取 n 次, 共计 m × k × n 次 32bit Global Memory Load操作;
- 对 B 矩阵重复读取 m 次, 共计 k × n × m 次 32bit Global Memory Load操作;
- 对 C 矩阵共计 m × n 次 32bit Global Memory Store操作。
SGEMM w/ smem
利用 Shared Mem 对 SGEMM 进行优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
__global__ void sgemmKernelV1(float* __restrict__ a, float* __restrict__ b, float* __restrict__ c,
const int M, const int N, const int K, const float alpha, const float beta
){
const int TILE_SIZE = 16;
int m = blockIdx.x * blockDim.x + threadIdx.x;
int n = blockIdx.y * blockDim.y + threadIdx.y;
__shared__ float sa[TILE_SIZE][TILE_SIZE];
__shared__ float sb[TILE_SIZE][TILE_SIZE];
float tileSum = 0.0f;
int nIter = (K + TILE_SIZE - 1) / TILE_SIZE;
for (int i = 0; i < nIter; ++i){
sa[threadIdx.x][threadIdx.y] = (m < M && (i * TILE_SIZE + threadIdx.y) < K) ? a[OFFSET(m, i * TILE_SIZE + threadIdx.y, K)] : 0.0f;
sb[threadIdx.x][threadIdx.y] = (n < N && (i * TILE_SIZE + threadIdx.x) < K) ? b[OFFSET(i * TILE_SIZE + threadIdx.x, n, N)] : 0.0f;
__syncthreads();
for (int j = 0; j < TILE_SIZE; ++j){
tileSum += sa[threadIdx.x][j] * sb[j][threadIdx.y];
}
__syncthreads();
}
if (m < M && n < N) {
c[m * N + n] = alpha * tileSum + beta * c[m * N + n];
}
}
每个线程计算 (TM, TN) 个元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
// #define FLOAT4(pointer) (reinterpret_cast<float4*>(&(pointer))[0])
/*
const int BM = 128;
const int BN = 128;
const int BK = 8;
const int TM = 8;
const int TN = 8;
dim3 block = dim3(BN / TN, BM / TM);
dim3 grid = dim3((N + BN - 1) / BN, (M + BM - 1) / BM);
*/
template<const int BM, const int BN, const int BK, const int TM, const int TN>
__global__ void sgemmKernelV2(
float* A, float* B, float* C,
const int M, const int N, const int K,
const float alpha, const float beta
){
int tid = threadIdx.y * blockDim.x + threadIdx.x;
__shared__ float sa[BM][BK];
__shared__ float sb[BK][BN];
int load_a_smem_m = tid / (BK / 4);
int load_a_smem_k = (tid % (BK / 4)) * 4;
int load_b_smem_k = tid / (BN / 4);
int load_b_smem_n = (tid % (BN / 4)) * 4;
int load_a_gmem_m = blockIdx.y * BM + load_a_smem_m;
int load_b_gmem_n = blockIdx.x * BN + load_b_smem_n;
float tileSum[TM][TN] = {0.0};
int nIter = (K + BK - 1) / BK;
for (int bk = 0; bk < nIter; ++bk){
int load_a_gmem_k = bk * BK + load_a_smem_k;
FLOAT4(sa[load_a_smem_m][load_a_smem_k]) = FLOAT4(A[OFFSET(load_a_gmem_m, load_a_gmem_k, K)]);
int load_b_gmem_k = bk * BK + load_b_smem_k;
FLOAT4(sb[load_b_smem_k][load_b_smem_n]) = FLOAT4(B[OFFSET(load_b_gmem_k, load_b_gmem_n, N)]);
__syncthreads();
#pragma unroll
for (int k = 0; k < BK; ++k){
#pragma unroll
for (int tm = 0; tm < TM; ++tm){
#pragma unroll
for (int tn = 0; tn < TN; ++tn){
tileSum[tm][tn] += sa[threadIdx.y * TM + tm][k] * sb[k][threadIdx.x * TN + tn];
}
}
}
__syncthreads();
}
// write back to gmem
#pragma unroll
for (int i = 0; i < TM; ++i){
int store_c_gmem_m = blockIdx.y * BM + threadIdx.y * TM + i;
#pragma unroll
for (int j = 0; j < TN; j+=4){
int store_c_gmem_n = blockIdx.x * BN + threadIdx.x * TN + j;
int store_c_gmem_addr = OFFSET(store_c_gmem_m, store_c_gmem_n, N);
FLOAT4(C[store_c_gmem_addr]) = FLOAT4(tileSum[i][j]);
}
}
}
解决 Bank Conflict 问题
上节通过利用 Shared Memory 大幅提高了访存效率,进而提高了性能,本节将进一步优化 Shared Memory 的使用。
Shared Memory一共划分为32个Bank,每个Bank的宽度为4 Bytes,如果需要访问同一个Bank的多个数据,就会发生Bank Conflict。例如一个Warp的32个线程,如果访问的地址分别为0、4、8、…、124,就不会发生Bank Conflict,只占用Shared Memory一拍的时间;如果访问的地址为0、8、16、…、248,这样一来地址0和地址128对应的数据位于同一Bank、地址4和地址132对应的数据位于同一Bank,以此类推,那么就需要占用Shared Memory两拍的时间才能读出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
// #define FLOAT4(pointer) (reinterpret_cast<float4*>(&(pointer))[0])
/*
const int BM = 128;
const int BN = 128;
const int BK = 8;
const int TM = 8;
const int TN = 8;
dim3 block = dim3(BN / TN, BM / TM);
dim3 grid = dim3((N + BN - 1) / BN, (M + BM - 1) / BM);
*/
template<const int BM, const int BN, const int BK, const int TM, const int TN>
__global__ void sgemmKernelV3(float* __restrict__ a, float* __restrict__ b, float* __restrict__ c,
const int M, const int N, const int K, const float alpha, const float beta
){
const int bx = blockIdx.x;
const int by = blockIdx.y;
const int tx = threadIdx.x;
const int ty = threadIdx.y;
const int tid = ty * blockDim.x + tx;
__shared__ float s_a[BK][BM];
__shared__ float s_b[BK][BN];
float r_load_a[4];
float r_load_b[4];
float r_comp_a[TM];
float r_comp_b[TN];
float r_c[TM][TN] = {0.0};
int load_a_smem_m = tid >> 1;
int load_a_smem_k = (tid & 1) << 2;
int load_b_smem_k = tid >> 5;
int load_b_smem_n = (tid & 31) << 2;
int load_a_gmem_m = by * BM + load_a_smem_m;
int load_b_gmem_n = bx * BN + load_b_smem_n;
for (int bk = 0; bk < (K + BK - 1) / BK; bk++) {
int load_a_gmem_k = bk * BK + load_a_smem_k;
int load_a_gmem_addr = OFFSET(load_a_gmem_m, load_a_gmem_k, K);
int load_b_gmem_k = bk * BK + load_b_smem_k;
int load_b_gmem_addr = OFFSET(load_b_gmem_k, load_b_gmem_n, N);
FLOAT4(r_load_a[0]) = FLOAT4(a[load_a_gmem_addr]);
FLOAT4(r_load_b[0]) = FLOAT4(b[load_b_gmem_addr]);
s_a[load_a_smem_k ][load_a_smem_m] = r_load_a[0];
s_a[load_a_smem_k + 1][load_a_smem_m] = r_load_a[1];
s_a[load_a_smem_k + 2][load_a_smem_m] = r_load_a[2];
s_a[load_a_smem_k + 3][load_a_smem_m] = r_load_a[3];
FLOAT4(s_b[load_b_smem_k][load_b_smem_n]) = FLOAT4(r_load_b[0]);
__syncthreads();
#pragma unroll
for (int tk = 0; tk < BK; tk++) {
FLOAT4(r_comp_a[0]) = FLOAT4(s_a[tk][ty * TM / 2 ]);
FLOAT4(r_comp_a[4]) = FLOAT4(s_a[tk][ty * TM / 2 + BM / 2]);
FLOAT4(r_comp_b[0]) = FLOAT4(s_b[tk][tx * TN / 2 ]);
FLOAT4(r_comp_b[4]) = FLOAT4(s_b[tk][tx * TN / 2 + BN / 2]);
#pragma unroll
for (int tm = 0; tm < TM; tm++) {
#pragma unroll
for (int tn = 0; tn < TN; tn++) {
r_c[tm][tn] += r_comp_a[tm] * r_comp_b[tn];
}
}
}
__syncthreads();
}
#pragma unroll
for (int i = 0; i < TM / 2; i++) {
int store_c_gmem_m = by * BM + ty * TM / 2 + i;
int store_c_gmem_n = bx * BN + tx * TN / 2;
int store_c_gmem_addr = OFFSET(store_c_gmem_m, store_c_gmem_n, N);
FLOAT4(c[store_c_gmem_addr]) = FLOAT4(r_c[i][0]);
FLOAT4(c[store_c_gmem_addr + BN / 2]) = FLOAT4(r_c[i][4]);
}
#pragma unroll
for (int i = 0; i < TM / 2; i++) {
int store_c_gmem_m = by * BM + BM / 2 + ty * TM / 2 + i;
int store_c_gmem_n = bx * BN + tx * TN / 2;
int store_c_gmem_addr = OFFSET(store_c_gmem_m, store_c_gmem_n, N);
FLOAT4(c[store_c_gmem_addr]) = FLOAT4(r_c[i + TM / 2][0]);
FLOAT4(c[store_c_gmem_addr + BN / 2]) = FLOAT4(r_c[i + TM / 2][4]);
}
}
Reference
[1] https://zhuanlan.zhihu.com/p/657632577
[2] DefTruth, Many Others. LeetCUDA: A Modern CUDA Learn Notes with PyTorch for Beginners. 2025. https://github.com/xlite-dev/LeetCUDA.git.