CUDA-Operators-4-Softmax
1. Softmax 基本实现
Softmax 将一个数值向量归一化为一个概率分布向量,且各个概率之和为 1。Softmax 可以用来作为神经网络的最后一层,用于多分类问题的输出。
原始 Softmax 中 $\sum e^{x_i}$ 容易导致数值溢出,通常使用 Safe Softmax,即让 $x_i - max(x)$,以防止数值溢出,具体公式表达如下所示。
\[m = max(x)\] \[Softmax(x) = \frac{e^{x_i-m}}{\sum e^{x_i-m}}\]Softmax 中需要执行三次循环,最关键是 max 和 sum 两个 reduce 操作。要完成计算需要读入三次,写一次,算法如下所示。
1 $m \gets -\infty$
2 for $i \gets 1$ to $N$ do
3 $m \gets \max(m, x_i)$
4 $s \gets 0$
5 for $i \gets 1$ to $N$ do
6 $s \gets s + e^{x_i - m}$
7 for $i \gets 1$ to $N$ do
8 $y_i \gets \dfrac{e^{x_i - m}}{s}$
1.1 Naive GPU 实现 (V1)
由于 Norm 过程依赖归约的结果,最 Naive 的实现就是一个线程算结果中一行,一个 block 算 BLOCK_SIZE 行,代码如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/**
* Every block calculate `BLOCK_SIZE` lines of result, one thread calculate one line
* inp is (N, C)
* out is (N, C)
* BLOCK_SIZE = 32
* dim3 block(BLOCK_SIZE)
* dim3 grid((N + BLOCK_SIZE -1) / BLOCK_SIZE)
*/
__global__ void softmax_forward_naive_f32_kernel(
float* out, const float* inp, int N, int C
) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
const float* inp_row = inp + i * C;
float* out_row = out + i * C;
float maxval = -INFINITY;
for (int j = 0; j < C; j++) {
if (inp_row[j] > maxval) {
maxval = inp_row[j];
}
}
double sum = 0.0;
for (int j = 0; j < C; j++) {
out_row[j] = expf(inp_row[j] - maxval);
sum += out_row[j];
}
for (int j = 0; j < C; j++) {
out_row[j] /= (float)sum;
}
}
}
1.2 Shared mem 实现 (V2)
V1 版本实现过于 Naive,每个线程算一行,导致:(1)单个线程任务很重,并行性不足;(2)三次访存都从 global mem 取,访存效率低。
下面的优化版本中,让每个 block 计算一行元素,并使用 shared mem 缓存归约结果。代码如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
/**
* Every block calculate one line.
* inp is (N, C)
*
* BLOCK_SZIE = 512
* dim3 grid(N)
* dim3 block(BLOCK_SIZE)
* size_t smem_size = BLOCK_SIZE * sizeof(float)
* softmax_forward_smem_f32_kernel<<<grid, block, smem_size>>>(out, inp, N, C);
*/
__global__ void softmax_forward_smem_f32_kernel(
float* out, const float* inp, int N, int C
){
extern __shared__ float shared[];
int idx = blockIdx.x; // ranges [0, N)
int tid = threadIdx.x; // ranges [0, block_size)
int block_size = blockDim.x;
const float* x = inp + idx * C;
float maxval = -INFINITY;
for (int i = tid; i < C; i += block_size) {
maxval = fmaxf(maxval, x[i]);
}
shared[tid] = maxval;
__syncthreads();
// max reductions
for (int stride = block_size / 2; stride >= 1; stride /= 2) {
if (tid < stride) {
shared[tid] = fmaxf(shared[tid], shared[tid + stride]);
}
__syncthreads();
}
float offset = shared[0];
float sumval = 0.0f;
for (int i = tid; i < C; i += block_size) {
sumval += expf(x[i] - offset);
}
shared[tid] = sumval;
__syncthreads();
// sum reduction
for (int stride = block_size / 2; stride >= 1; stride /= 2) {
if (tid < stride) {
shared[tid] += shared[tid + stride];
}
__syncthreads();
}
// broadcast the sum to all threads in the block
float sum = shared[0];
for (int i = tid; i < C; i += block_size) {
out[idx * C + i] = expf(x[i] - offset) / sum;
}
}
1.3 Shared mem + Warp Reduce 优化 (V3)
归约过程可以使用 warp reduce 直接在寄存器中实现优化,分块为 grid((N + BN - 1) / BN) 和 block(BC, BN)。即每个 block 计算 BN 行结果,每个线程处理 (C + BC - 1) / BC 个数,线程视角的归约计算流程如下所示。 block 归约也是同样的过程:warp 内归约,然后写入 shared mem, 最后 shared mem 广播。
- 每个线程计算 (C + BC - 1) / BC 个数,即初步归约到 0…BC-1 线程;
- 对 0…BC-1 线程的每个 warp 做 warp reduce,每个 warp 的结果缓存在 smem 中;
- 然后 0 号线程归约每个 warp 的结果,得到归约结果,写入 0 号线程对应的 smem 中;
- 需要使用时,从 smem 中取出,即 smem 广播的过程;
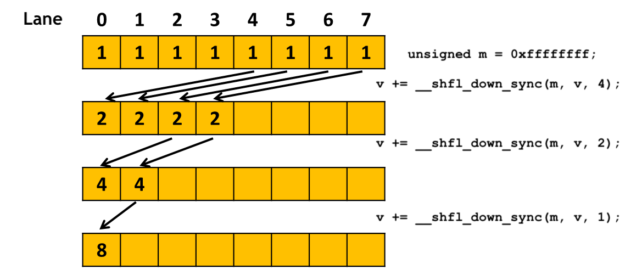
具体代码如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
#define WarpSize 32
/**
* Every Block calculate BN lines
* BN = 4
* BC = 256 -> a multiple of 32
* inp(N, C)
* grid((N + BN - 1) / BN)
* block(BC, BN)
*/
template <const int BN, const int BC>
__global__ void softmax_forward_warp_smem_f32_kernel(
float* out, const float* inp, int N, int C
){
// shared memory is used for inter-warp reduction
__shared__ float smem[BN][2][BC];
int tx = threadIdx.x;
int ty = threadIdx.y;
int bx = blockIdx.x;
int n = bx * BN + ty;
int lane_id = tx % WarpSize;
int warp_id = tx / WarpSize;
if (n >= N) return;
const int niter = BC / WarpSize;
const float* gmem = inp + n * C;
// 1.max reduction
float max = -INFINITY;
for (int i = tx; i < C; i += BC){
max = fmaxf(max, gmem[i]);
}
max = fmaxf(max, __shfl_down_sync(0xffffffff, max, 16));
max = fmaxf(max, __shfl_down_sync(0xffffffff, max, 8));
max = fmaxf(max, __shfl_down_sync(0xffffffff, max, 4));
max = fmaxf(max, __shfl_down_sync(0xffffffff, max, 2));
max = fmaxf(max, __shfl_down_sync(0xffffffff, max, 1));
if (lane_id == 0) smem[ty][0][warp_id] = max;
__syncthreads();
if (tx == 0) {
int maxval = smem[ty][0][0];
for (int i = 1; i < niter; ++i){
maxval = fmaxf(maxval, smem[ty][0][i]);
}
smem[ty][0][0] = maxval;
}
__syncthreads();
// 2.sum reduction
float offset = smem[ty][0][0]; // broadcast maxval
float sum = 0;
for (int i = tx; i < C; i += BC){
sum += expf(gmem[i] - offset);
}
sum += __shfl_xor_sync(0xffffffff, sum, 16);
sum += __shfl_xor_sync(0xffffffff, sum, 8);
sum += __shfl_xor_sync(0xffffffff, sum, 4);
sum += __shfl_xor_sync(0xffffffff, sum, 2);
sum += __shfl_xor_sync(0xffffffff, sum, 1);
if (lane_id == 0) smem[ty][1][warp_id] = sum;
__syncthreads();
if (tx == 0){
float sumval = smem[ty][1][0];
for (int i = 1; i < niter; ++i){
sumval += smem[ty][1][i];
}
smem[ty][1][0] = sumval;
}
__syncthreads();
// 3.norm
float sumval = smem[ty][1][0];
for (int i = tx; i < C; i += BC){
out[n * C + i] = expf(gmem[i] - offset) / sumval;
}
}
2. Softmax 高阶优化
Online softmax [4] 通过累加迭代计算,能够省略一次循环并实现 safe softmax 的等价计算。核心思想是利用指数计算特性,把第 i 步 max 值套入到 i-1 步 sum exp 中,再加上当前的 $exp(x_i-max_i)$ 即为第 i 步 sum exp。
1 $m_0 \gets -\infty$
2 $s_0 \gets 0$
3 for $i \gets 1$ to $N$ do
4 $m_i \gets \max(m_{i-1}, x_i)$
5 $s_i \gets s_{i-1} \cdot e^{\,m_{i-1} - m_i\,} + e^{\,x_i - m_i\,}$
6 end for
7 for $i \gets 1$ to $N$ do
8 $y_i \gets \dfrac{e^{x_i - m_N}}{s_N}$
9 end for
\[logSoftmax(x) = log(\frac{e^{x_i-x_{max}}}{\sum_j(e^{x_j-x_{max}})}) = x_i - x_m -log(\sum_j e^{x_j-x_{max}})\]NOTE: logSoftmax 同样能用上面的 sum exp 性质进行优化。
2.1 协作组 + 结构体实现 (V4)
下面是 协作组 + 结构体 的简单实现,当 C 维度较大时,单个线程任务过重,导致线程资源紧张,并行性会下降。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
#include <cooperative_groups.h>
#include <cooperative_groups/reduce.h>
namespace cg = cooperative_groups;
struct __align__(8) SumMax
{
float maxval;
float sum;
};
__device__ __inline__ SumMax reduce_sum_max_op(SumMax a, SumMax b) {
bool a_bigger = (a.maxval > b.maxval);
SumMax bigger_m = a_bigger ? a : b;
SumMax smaller_m = a_bigger ? b : a;
SumMax res;
res.maxval = bigger_m.maxval;
res.sum = bigger_m.sum + smaller_m.sum * expf(smaller_m.maxval - bigger_m.maxval);
return res;
}
/**
* Every warp calculate one line.
* BLOCK → a multiple of 32
* dim3 grid((N + BLOCK_SIZE / 32 - 1) / (BLOCK_SIZE / 32))
* dim3 block(BLOCK_SIZE)
*/
__global__ void softmax_forward_online_kernel(
float* out, const float* inp, int N, int C
){
cg::thread_block block = cg::this_thread_block();
cg::thread_block_tile<32> warp = cg::tiled_partition<32>(block);
int idx = blockIdx.x * warp.meta_group_size() + warp.meta_group_rank();
if (idx >= N) {
return;
}
const float* x = inp + idx * C;
SumMax sm_partial;
sm_partial.maxval = -INFINITY;
sm_partial.sum = 0.0f;
for (int i = warp.thread_rank(); i < C; i += warp.size()) {
sm_partial = reduce_sum_max_op(sm_partial, { x[i], 1.0f });
}
SumMax sm_total = cg::reduce(warp, sm_partial, reduce_sum_max_op);
// __stcs → st.global.cs SASS 忽略 L1,写到 global mem (只走 L2/DRAM)
for (int i = warp.thread_rank(); i < C; i += warp.size()) {
__stcs(out + idx * C + i, expf(x[i] - sm_total.maxval) / sm_total.sum);
}
}
上面的代码难点在 reduce_sum_max_op 函数中,这个 reduce 代码本质是合并两段 exp sum。假设 A 和 B 是两个 SumMax 数据结构,我们的目标是求 A 和 B 最大值下的 safe exp sum。
首先,我们需要比较最大值,假设 A 大,此时我们的目标是将 B 转化为 $\sum e^{x_j-a.maxval}$ 形式。因此,根据指数性质,得:
\[\sum e^{x_j-a.maxval} = \sum e^{x_j-b.maxval}\cdot e^{b.maxval-a.maxval} = b.sum\cdot e^{b.maxval-a.maxval}\]所以合并计算过程如下所示:
\[sum'= a.sum + b.sum\cdot e^{b.maxval-a.maxval}\]Reference
[1] LeetCUDA
[2] ops(2):SoftMax算子的 CUDA 实现.
[3] Attention优化][2w字]📚原理篇: 从Online-Softmax到FlashAttention V1/V2/V3.