CUDA-Operators-6-Cumsum
1.Cumsum 理论
Prefix Sum 定义为:$y_i = \sum_0^i x_i$,在 CPU 上简单实现如下所示。
1
2
3
4
5
6
7
void PrefixSum(const int32_t* input, size_t n, int32_t* output) {
int32_t sum = 0;
for (size_t i = 0; i < n; ++i) {
sum += input[i];
output[i] = sum;
}
}
Cumsum 计算过程中,每个元素依赖上一个元素的值,如何并行计算呢?
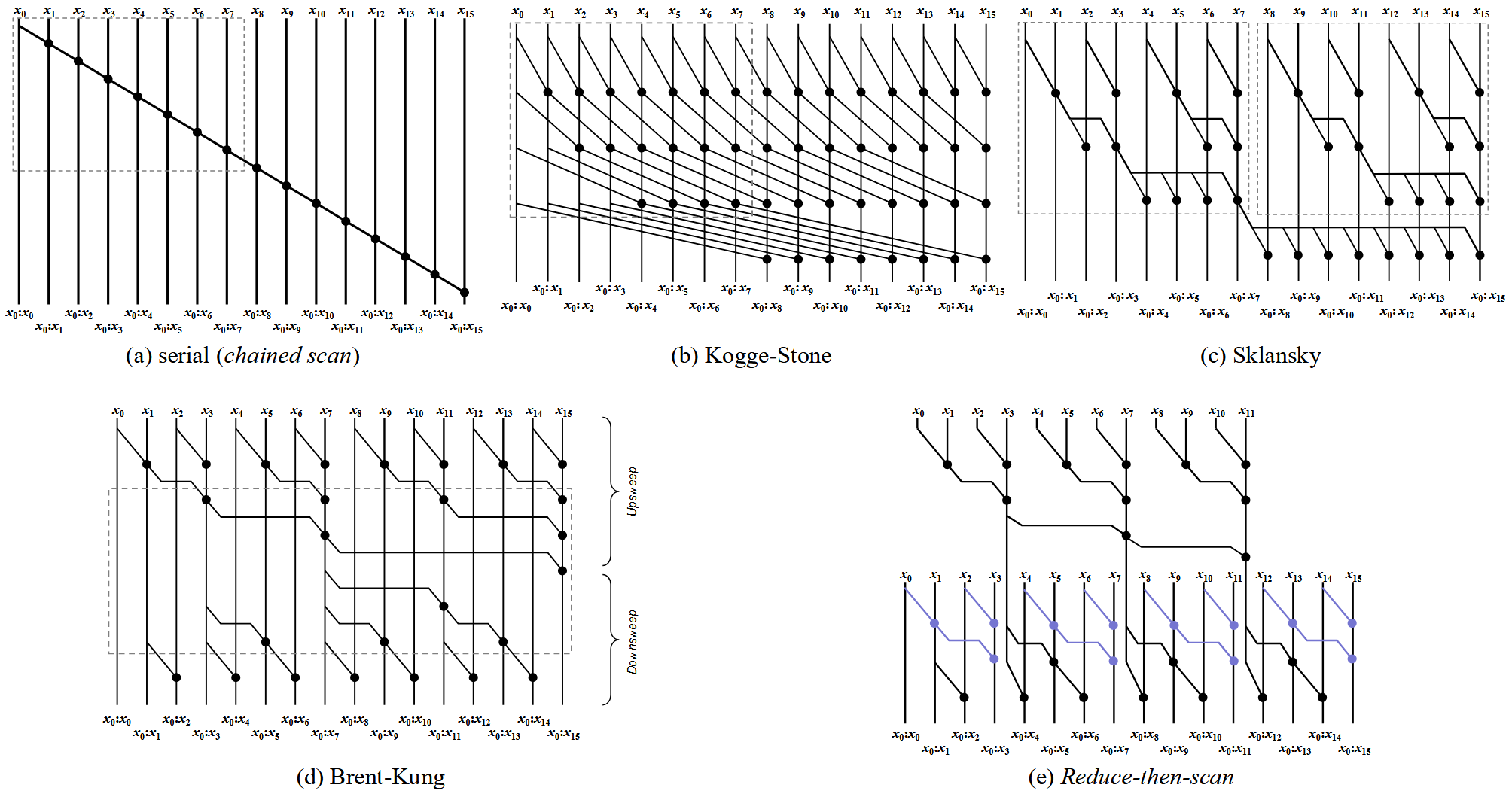
图 1 展示了当代前缀扫描算法相关的典型扫描网络结构。复杂度来源于“深度 + 规模”。具体内容可参考论文 [1]。
- 图 1(a) 没有并行机会,但最小 n-1 的规模在处理器计算能力远大于输入规模时,极具吸引力。通过增加线程计算粒度(每个线程多处理几个数)来减少线程间通信,是提升处理器利用率的常用技术。
- 图 1(b) 规模为低效的 $O(nlog_2n)$,但较浅的深度和简单的共享内存地址计算,是 warp 实现的理想策略。
- 图 1(c) 同样以 $O(nlog_2n)$ 规模实现了最小深度 $log_2n$。
- 图 1(d) 是一种高效的策略,具有$2log_2n$ 的深度和 $O(n)$ 的规模,其数据流在视觉上呈现”沙漏”形态,包含:(1) 并行度逐渐减小的归约阶段,(2) 并行度逐渐增加的向下传播。
- 图 1(e) 将向下传播的行为从传播转换为了扫描,先归约后扫描,需要一次额外的 $O(n)$ 开销。
当输入规模不超过处理器一次能并行处理的宽度时(如输入长度 ≤ 32),性能取决于深度。而对于大规模问题,每层涉及大量同步、内存访问、调度,最小规模网络则更为关键。
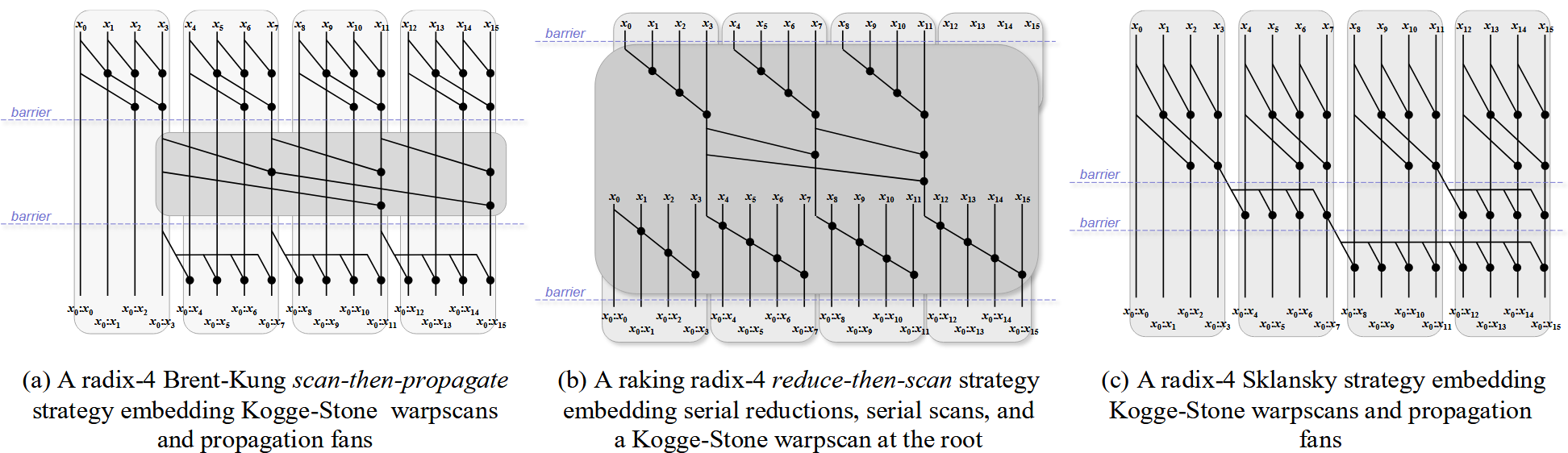
1.1 blcok 级扫描策略
基于上述算法和分析,block 级的策略一般有如下 3 种,具体如图 2 所示,图中以 warp = 4 展示了 blcok 级的扫描策略,虚线表示基于 shared mem 实现的同步。
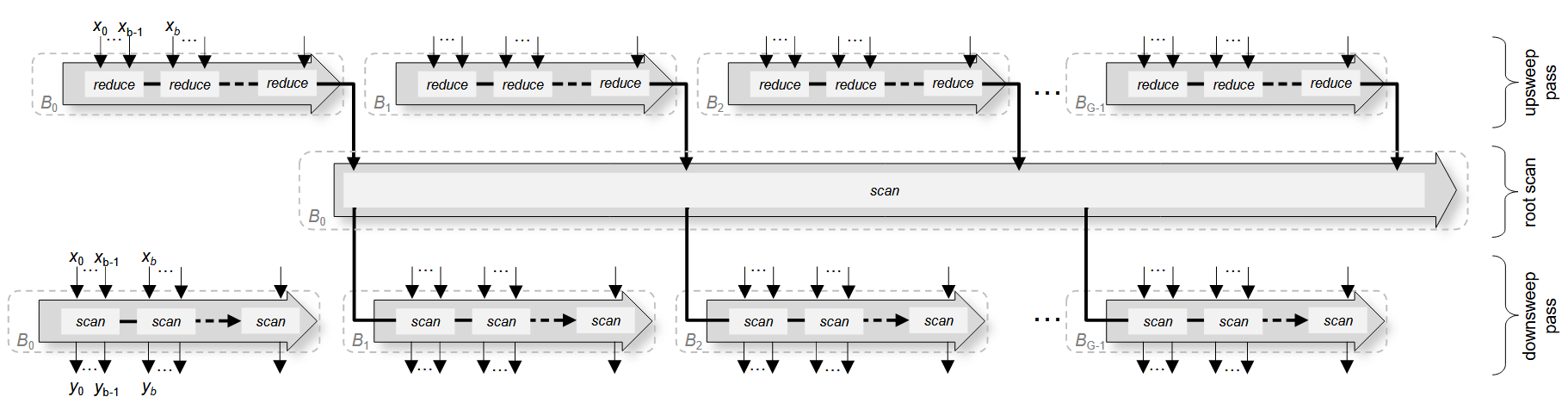
1.2 global 级扫描策略
Reduce-then-scan 策略,先调度 block 级归约内核,再调度 block 级扫描网络内核。如图 3 所示,输入被均匀划分为 G 个 block(G为处理器可同时驻留的块数,与n无关),分为 3 个内核实现。
- upsweep 中,各线程块以迭代串行方式归约其分块,随后在 root scan 中对 G 个块聚合结果进行扫描。
- downsweep 中,各线程块基于块聚合扫描生成的块前缀,迭代计算分块的前缀扫描。
如图 4 所示,链式扫描并行化中,每个线程块被分配一个输入数据块,且线程块之间存在串行依赖链。各线程块需等待其前驱的 block 前缀计算完成。 链式扫描的性能受限于线程块之间的信号传播延迟,会严重限制吞吐。
解决方案通常是增加 block size,但是这又会导致片上资源紧张,难以权衡。
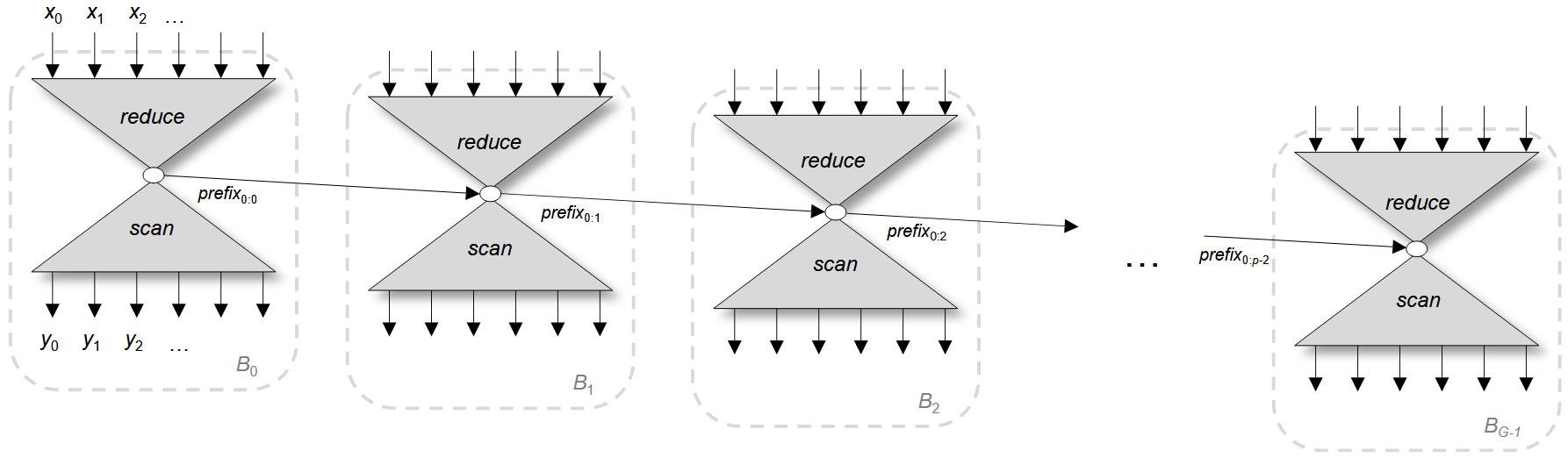
如图 5 所示,NVIDIA 提出的方法通过逐步引入冗余计算,解除对直接前驱的单一依赖,允许查看多个前驱状态。 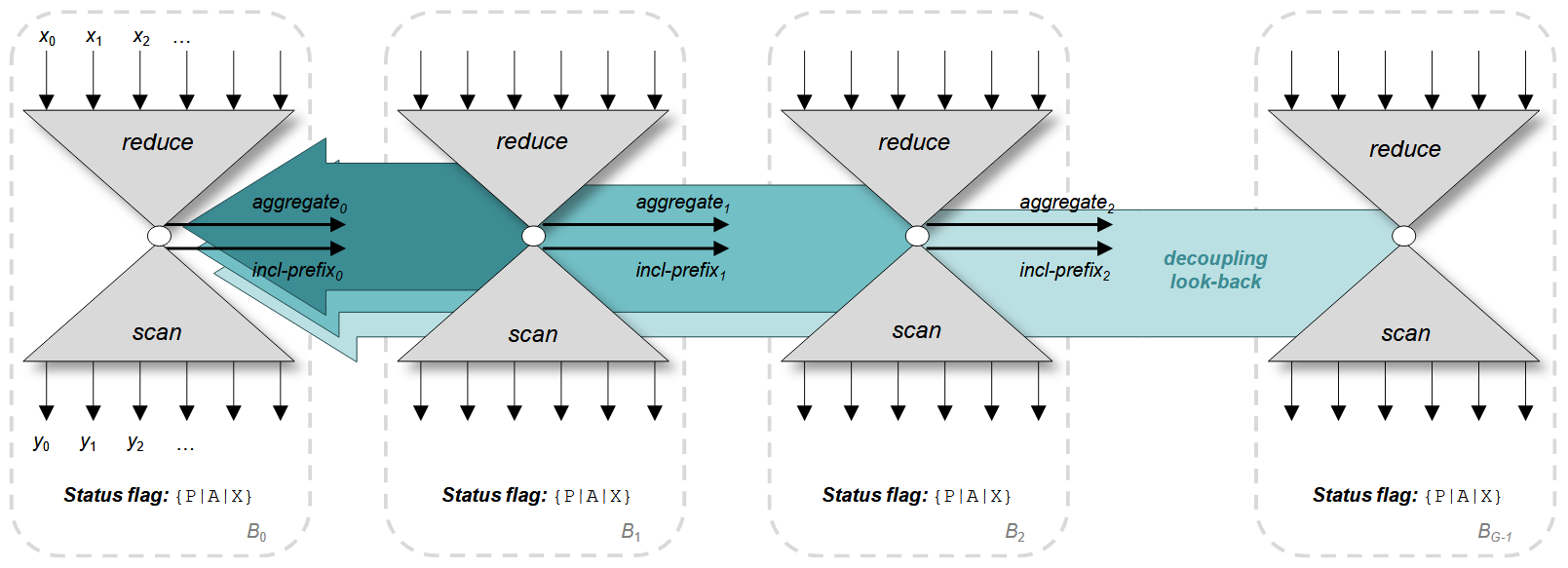
2.CUDA 实现
递归实现,先 Scan 每个 block,然后 写入 buffer 中(记录每个 block 的总和,然后递归归约 buffer,buffer 可能也挺大的),最后将 block 归约结果加到各个 block 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
__device__ int32_t ScanWarp(int32_t val) {
int32_t lane = threadIdx.x & 31;
#pragma unroll
for (int offset = 1; offset < 32; offset <<= 1) {
int32_t n = __shfl_up_sync(0xffffffff, val, offset);
if (lane >= offset) val += n;
}
return val;
}
__device__ __forceinline__ int32_t ScanBlock(int32_t val) {
int32_t lane = threadIdx.x & 31;
int32_t warp_id = threadIdx.x >> 5;
extern __shared__ int32_t smem[];
val = ScanWarp(val); // scan each warp
__syncthreads();
if (lane == 31) smem[warp_id] = val; // write sum of each warp to warp_sum
__syncthreads();
if (warp_id == 0) smem[lane] = ScanWarp(smem[lane]); // scan warp_sum
__syncthreads();
if (warp_id > 0) val += smem[warp_id - 1];
__syncthreads();
return val;
}
__global__ void ScanAndWritePartSumKernel(
const int32_t* input, int32_t* part, int32_t* output, size_t n, size_t part_num
){
for (size_t part_i = blockIdx.x; part_i < part_num; part_i += gridDim.x) {
size_t index = part_i * blockDim.x + threadIdx.x;
int32_t val = index < n ? input[index] : 0;
val = ScanBlock(val);
__syncthreads();
if (index < n) output[index] = val;
if (threadIdx.x == blockDim.x - 1) part[part_i] = val;
}
}
__global__ void AddBaseSumKernel(int32_t* part, int32_t* output, size_t n, size_t part_num){
for (size_t part_i = blockIdx.x; part_i < part_num; part_i += gridDim.x) {
if (part_i == 0) continue;
int32_t index = part_i * blockDim.x + threadIdx.x;
if (index < n) output[index] += part[part_i - 1];
}
}
void ScanThenFan(const int32_t* input, int32_t* buffer, int32_t* output, size_t n) {
size_t part_size = 1024; // tuned
size_t part_num = (n + part_size - 1) / part_size;
size_t block_num = std::min<size_t>(part_num, 128);
int32_t* part = buffer; // buffer[0:part_num] to save the metric of part
size_t shm_size = 32 * sizeof(int32_t);
ScanAndWritePartSumKernel<<<block_num, part_size, shm_size>>>(input, part, output, n, part_num);
if (part_num >= 2) {
ScanThenFan(part, buffer + part_num, part, part_num);
AddBaseSumKernel<<<block_num, part_size>>>(part, output, n, part_num);
}
}
reference
[1] Single-pass Parallel Prefix Scan with Decoupled Look-back
[2] CUB