LLM-Training-Overview
1.Pre-training
Pre-training 阶段主要是通过大量互联网语料,构建一个能够“记住”大量知识的基础模型。基础模型就是一个互联网 token 模拟器,并不具备 “根据问题,吐出对应答案” 的能力。
Step 1: download and preprocess the internet. Hugging face 开源了一个 44 TB 的 Pre-training 数据集 FineWeb。
Step 2: tokenization. LLMs 无法直接理解自然语言的文本,而分词器 (Tokenizer) 则是将自然语言转化成数字向量 (token)。 可视化 Tokenizer 网站:https://tiktokenizer.vercel.app/
Step 3: training. 根据互联网语料,最大化 next token 的概率,如 Fig 1 所示。 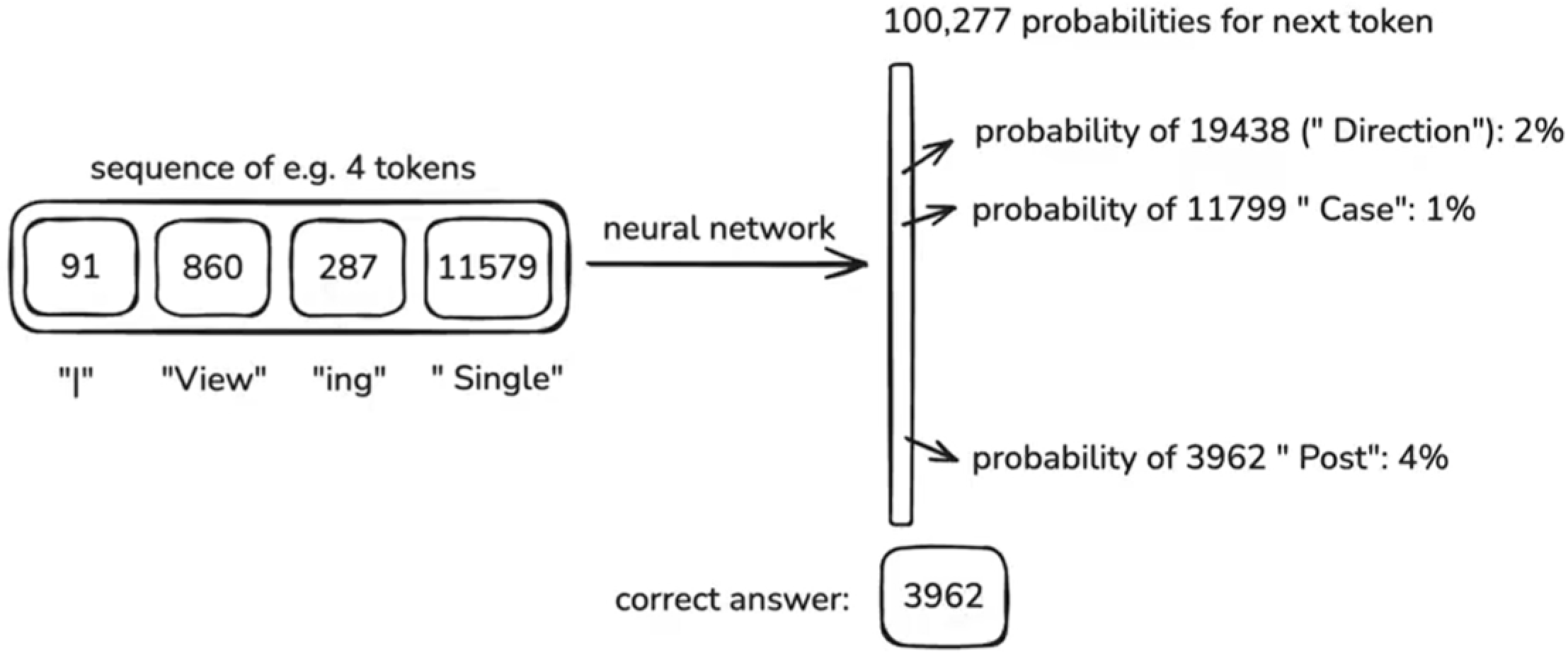
Inference. 基于 Pre-training 后的基础模型,输入 Token 序列,基础模型预测 next token。 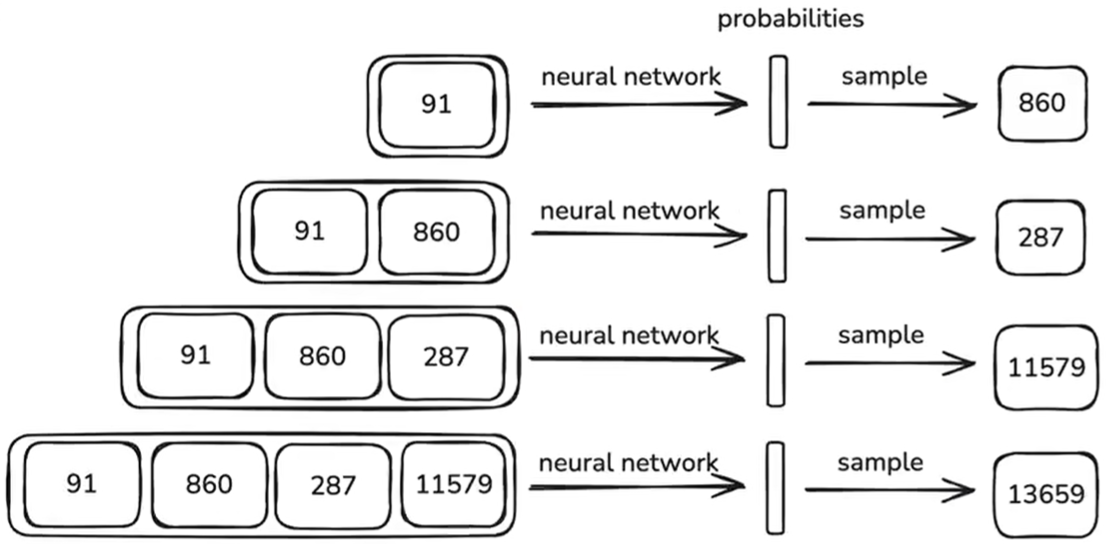
2.Post-training: SFT
与 Pre-training 阶段最大不同之处在于训练的语料。Post-training 的训练数据一般是对话(指令),且规模远小于 Pre-training 数据集,目的是同时内化 Pre-training 的知识和学习 Post-training 的对话形式。
Post-training 训练语料是回合制,LLMs(Assistance)和用户(User)轮回切换,并会用特殊字符标注开始和结束,示例如下:
1
2
3
4
<|im_start|>user<|im_sep|>What's 2+2?<|im_end|>
<|im_start|>assistant<|im_sep|>2+2 = 4<|im_end|>
<|im_start|>user<|im_sep|>what if it was *?<|im_end|>
<|im_start|>assistant<|im_sep|>2*2 = 4, same as 2+2!<|im_end|><|im_start|>assistant<|im_sep|>
实际上,这就是一维向量:
1
200264, 1428, 200266, 45350, 220, 17, 10, 17, 30, 200265, 198, 200264, 173781, 200266, 17, 10, 17, 314, 220, 19, 200265, 198, 200264, 1428, 200266, 13347, 538, 480, 673, 425, 30, 200265, 198, 200264, 173781, 200266, 17, 9, 17, 314, 220, 19, 11, 2684, 472, 220, 17, 10, 17, 0, 200265, 200264, 173781, 200266
2.1 幻觉
幻觉 (Hallucinations) 即 LLMs 面对训练数据集中未出现的问题时,会模仿训练数据中的输出格式,给出统计上最可能的猜测,实际上是乱编信息。
幻觉本质是训练语料缺失,常见的方案:
- 测试模型的知识边界,然后在数据中补全;
- 引入工具,允许模型刷新它的记忆或回忆。如下所示,现在模型通过嵌入特殊 token
<SEARCH_START>...<SEARCH_END>,触发搜索工具。
1
2
3
4
5
6
7
8
9
Human: "Who is Orson Kovacs?"
Assistant: "I'm sorry, l don't believe l know'
Mitigation #2
=> Allow the model to search!
Human: "Who is Orson Kovacs?"
Assistant:"<SEARCH_START>Who is Orson Kovacs?<SEARCHEND>
[...]
Orson Kovacs appears to be .."
此外,神经网络中的参数知识是一种模糊的记忆(vague recollection),而上下文窗口中的 tokens 则被称为 working memory。
2.2 Thinking
Thinking 过程主要作用是补充 working memory,使用更多的 token 来“模拟”问题步骤(仿照数据集中的推理步骤),从而提升最终答案的 token 概率。
例如,给出如下问题:
1
2
Human: "Emily buys 3 apples and 2 oranges. Eachorange costs $2. The total cost of all the fruit is $13.
What is the cost of apples?"
数据 A,偏向于先给出答案,实际上训出的大模型是在猜答案。由于 LLMs 推理时,token 是从左至右的计算方式(next token 依赖于已生成的 tokens 序列),后续用于推导过程的 token 在生成时,已经无法对答案 token 的计算产生实质性帮助。
1
2
Assistant: "The answer is $3. This is because 2 oranges at $2 are $4 total.
So the 3 apples cost $9, and thereforeeach apple is 9/3 = $3".
而数据 B 则能将答案 token 的计算分布到多个步骤中。
1
2
Assistant: "The total cost of the oranges is $4.13 -4 = 9,
the cost ofthe 3 apples is $9. 9/3 = 3, so eachapple costs $3. The answer is $3"
由于 token 基元的因素,LLMs 不擅长诸如计数,拼写,数值计算等问题,通常考虑硬编码或者调用工具两种解决方案。
Post-training: RL
用课本类比,base_model 是课本上的知识描述;SFT 是示例题目,包含了人类专家固定的步骤和答案,LLMs 只能尽可能地拟合,做出最佳猜测;而 RL 则是课后习题,给定了问题描述(Prompt)和最终答案,目的是训练 LLMs 吐出中间步骤的过程,并内化到 LLMs 中,如 Fig 3 所示。

RL 作用有两个:(1)增加 Working Memory,以更符合 LLMs 的 token sequence 得到正确的答案;(2)与人类偏好对齐。
得到正确答案。 一个问题往往具备多种解决方案(如下示例),但这些过程是人类标注的,实际上我们并不知道哪种 token sequence 是利于 LLMs 学习的; 而 RL 则允许 LLMs 反复尝试,以发现哪种 token sequence 能够确保给定提示,稳定地得到答案。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Emily buys 3 apples and 2 oranges. Each orange costs $2. Thetotal cost of all the fruit is $13. What is the cost of eachapple?
---
Set up a system of equations.
x= price of apples
3*X+2*2 = 13
3*x+4 = 13
3*X = 9
X=3
---
The oranges cost 2*2=4.
So the apples cost 13-4=9.
There are 3 apples.
So each apple costs 9/3 = 3.
13-4=9,9/3=3.
---
(13-4)/3 = 3.
---
Answer:$3
人类偏好对齐。 RL 的反馈来源于 reward,而人工对 LLMs 生成的每条序列进行打分是不现实的,RLHF 则是通过少量数据训练神经网络(Cost Model),以模拟人类评分。 Cost Model 的输入是 LLMs 生成的序列,输出一个 reward 数值标量。需要注意的是,Cost Model 是一个有损的人类偏好模拟器,过长的 RLHF 训练可能会误导 LLMs,比如最后输出 “the the the …” 的序列,需要在适当时候停止。 实际上,RLHF 并非传统意义上的 RL,更像一次微调。
Reference
[1] Andrej Karpathy. Deep Dive into LLMs like ChatGPT.
[2] Dubey A, Jauhri A, Pandey A, et al. The llama 3 herd of models[J]. arXiv e-prints, 2024: arXiv: 2407.21783.
[3] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.
[4] Guo D, Yang D, Zhang H, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning[J]. arXiv preprint arXiv:2501.12948, 2025.
[5] Ziegler D M, Stiennon N, Wu J, et al. Fine-tuning language models from human preferences[J]. arXiv preprint arXiv:1909.08593, 2019.